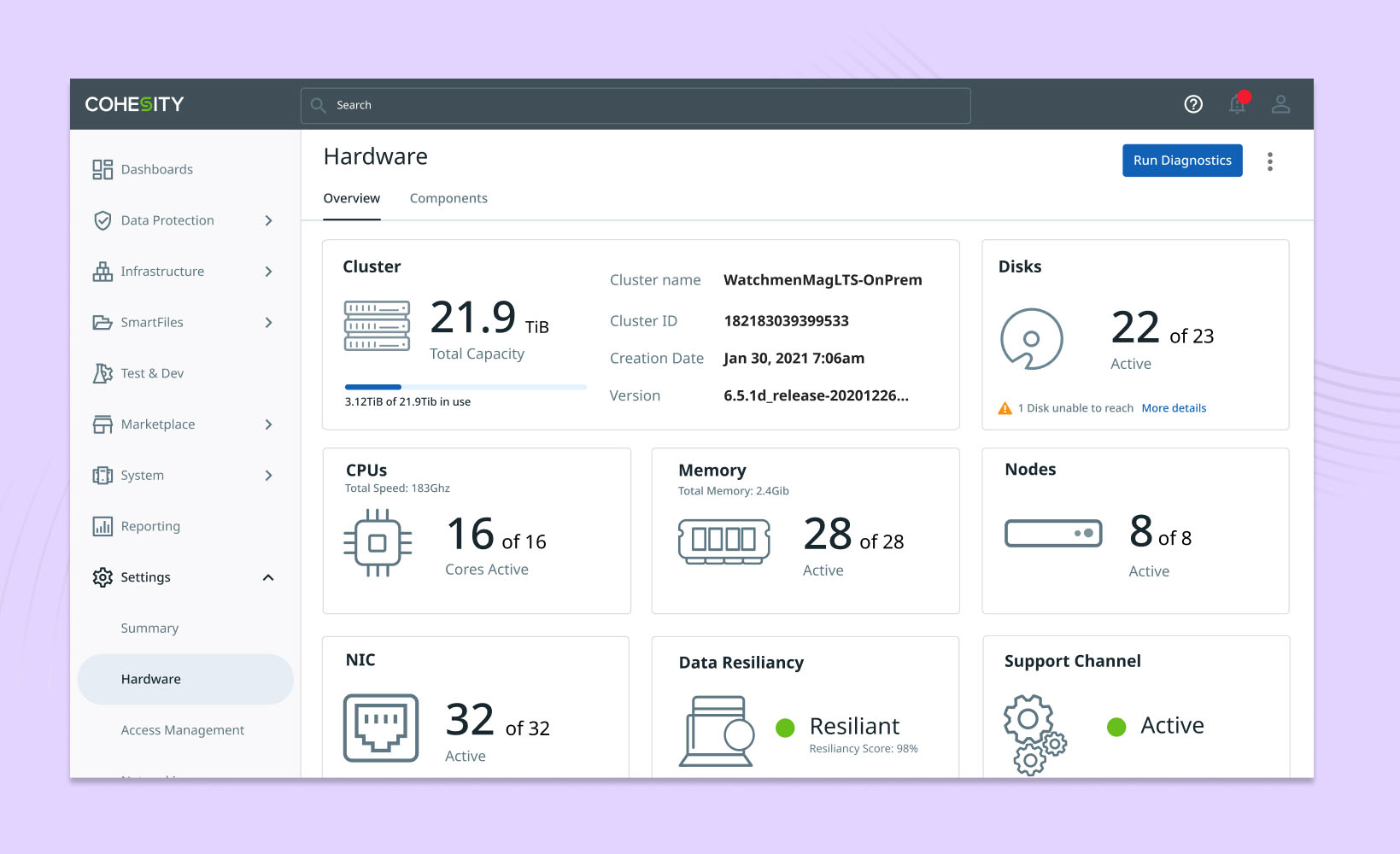
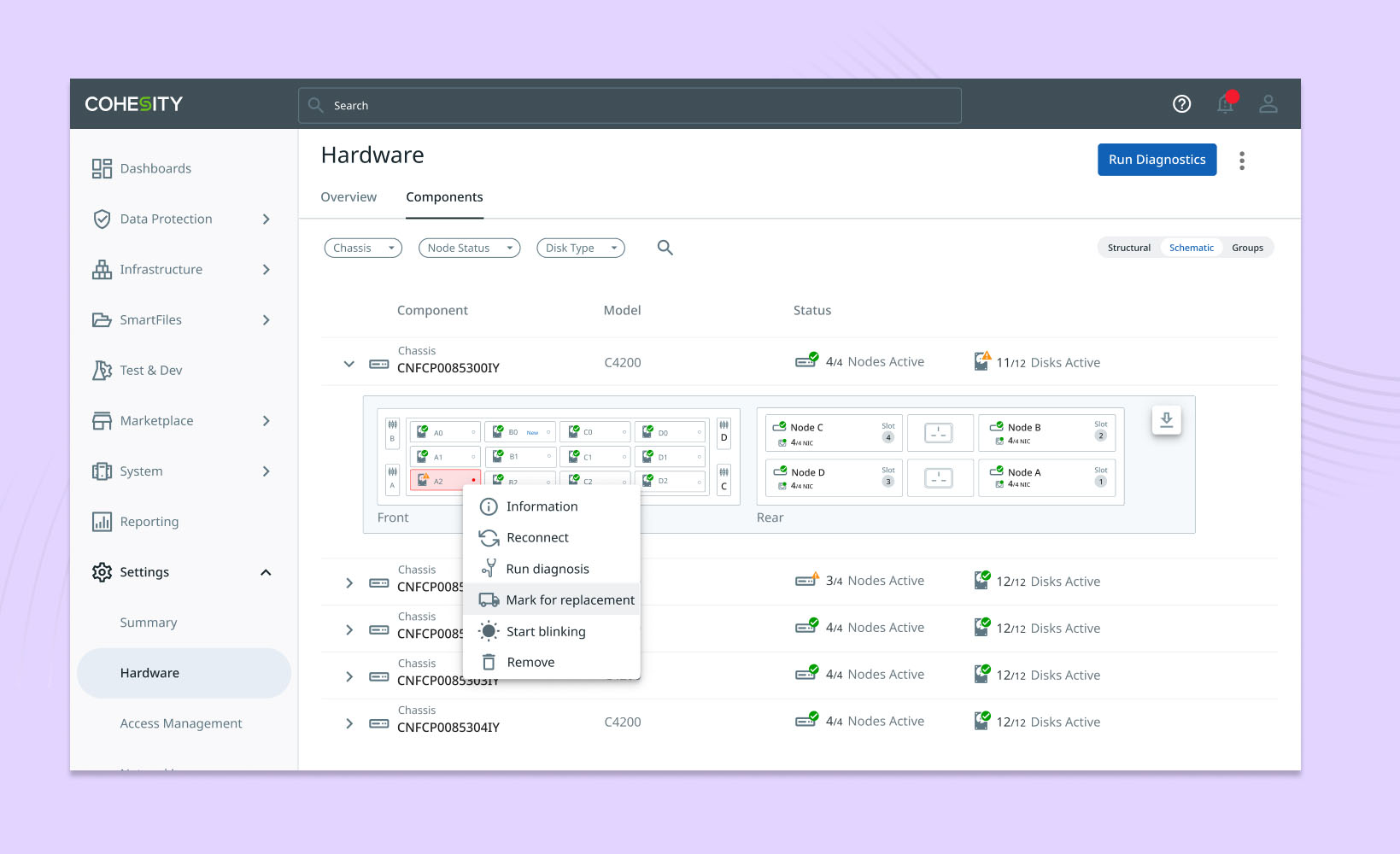
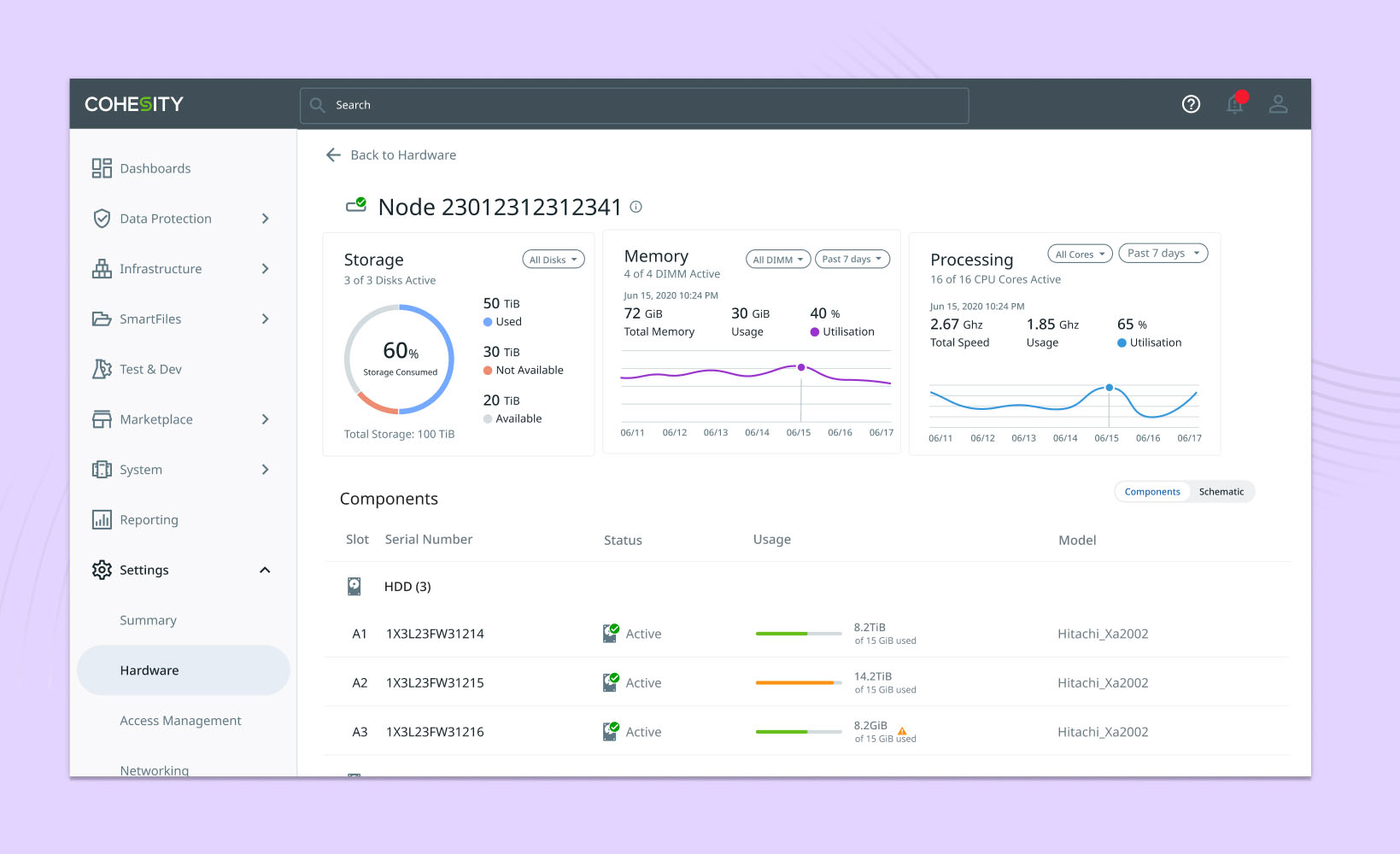
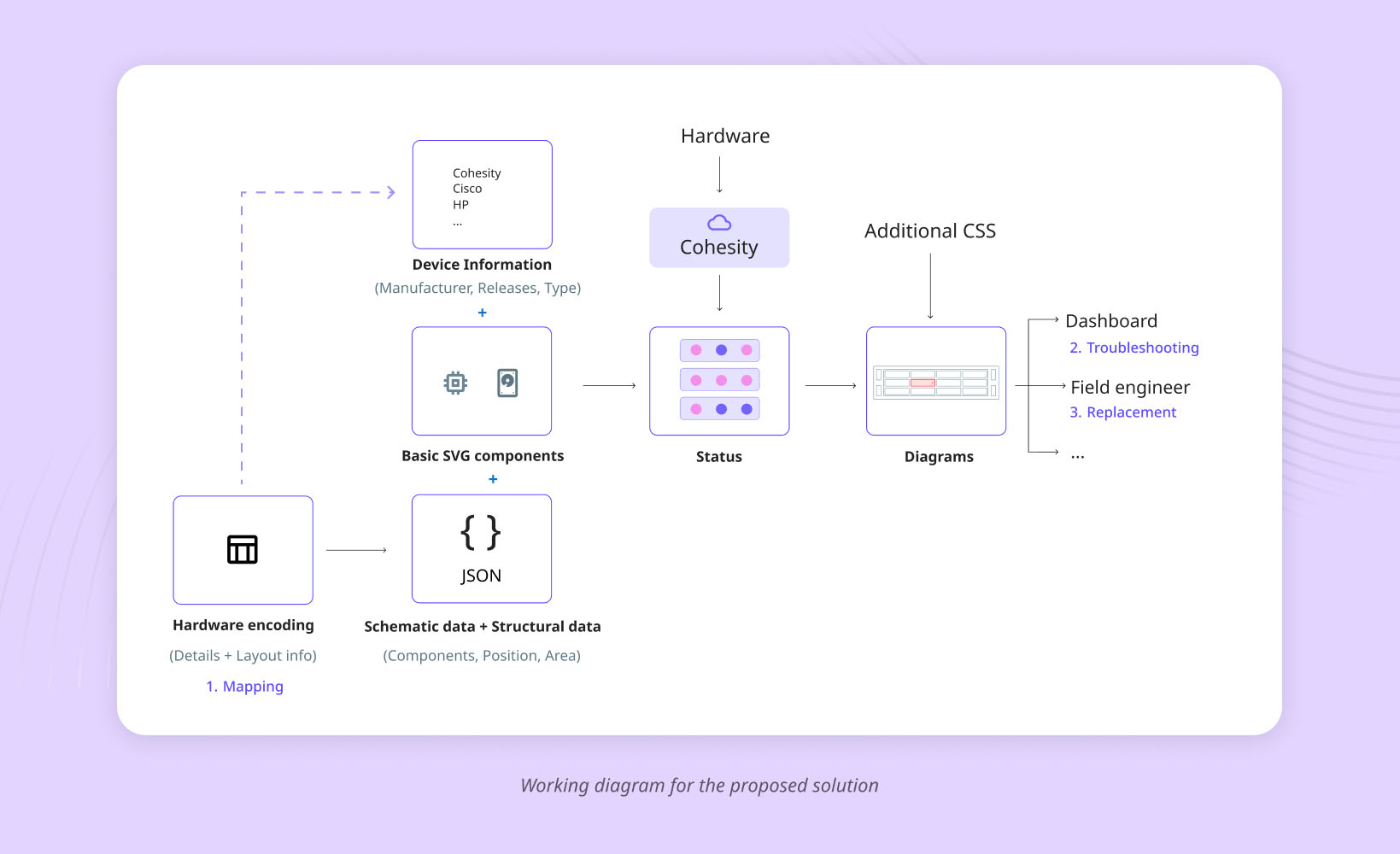
In data management, one of the common activities is maintaining the hardware infrastructure needed to support the digital layer of data. Due to various factors such as time, load, and manufacturing defects, hardware issues may arise, requiring attention and action to fix and ensure system performance.
The project involves a detailed study of the existing process and conducting interviews to understand the functions involved and current experiences. One major hardware-related problem is troubleshooting and identifying problematic hardware for repair or replacement. This difficulty stems from using static hardware manuals, the command-line interface to check status, and mentally mapping them with pictures from the manual. Additionally, communication of the identified hardware with the field engineers was unclear. To decrease troubleshooting time, reduce errors during replacement, and effectively utilize the support team's bandwidth, the project focuses on hardware health monitoring, troubleshooting hardware issues, and improving communication between the support team and field engineers for replacement cases. For supporting the above cases, there was a need to map a server cluster both logically and physically. This was achieved using an internal portal that acts as a central knowledge base for managing meta-information related to different supported models.